What was the central goal?
What I built
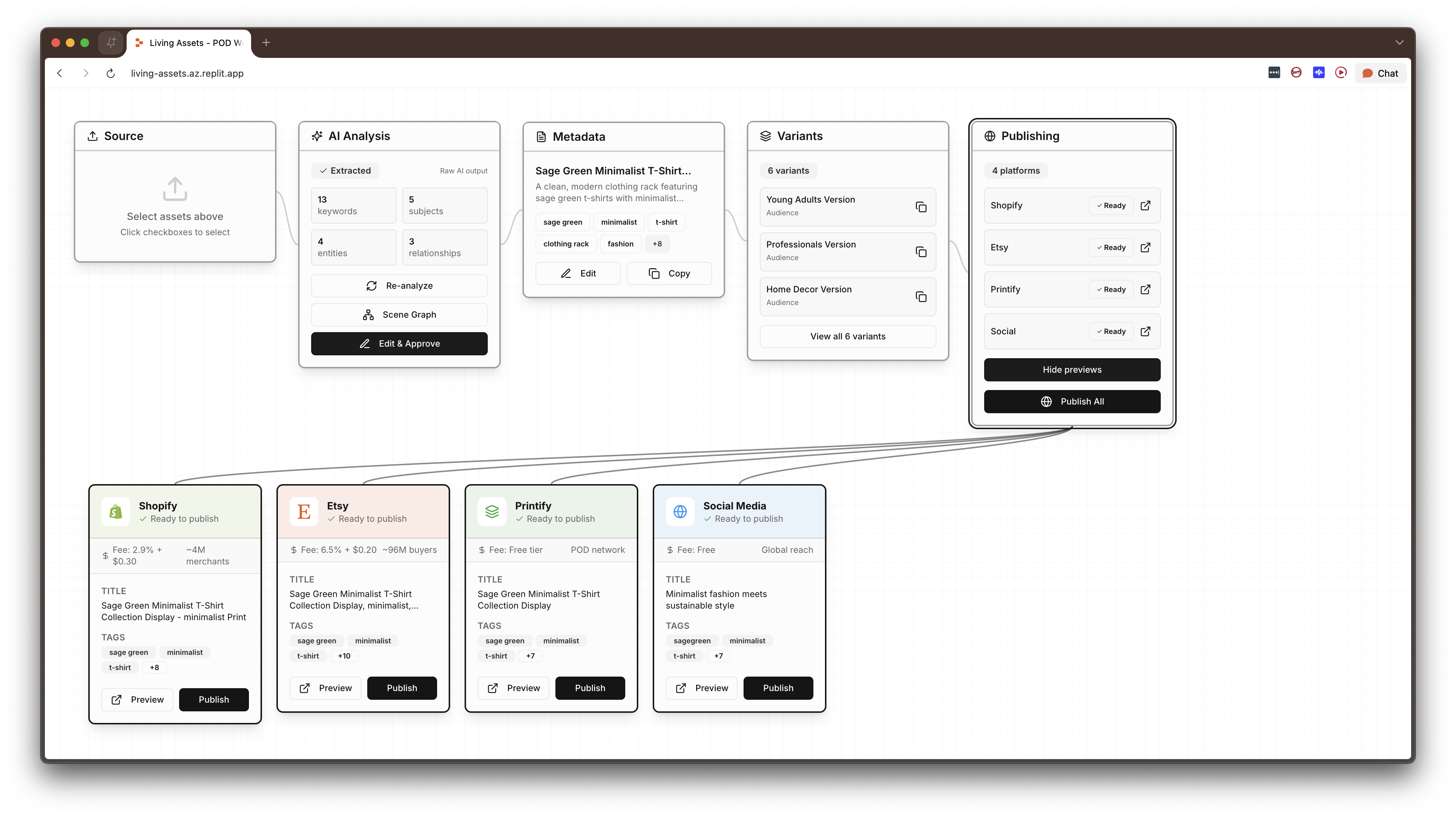
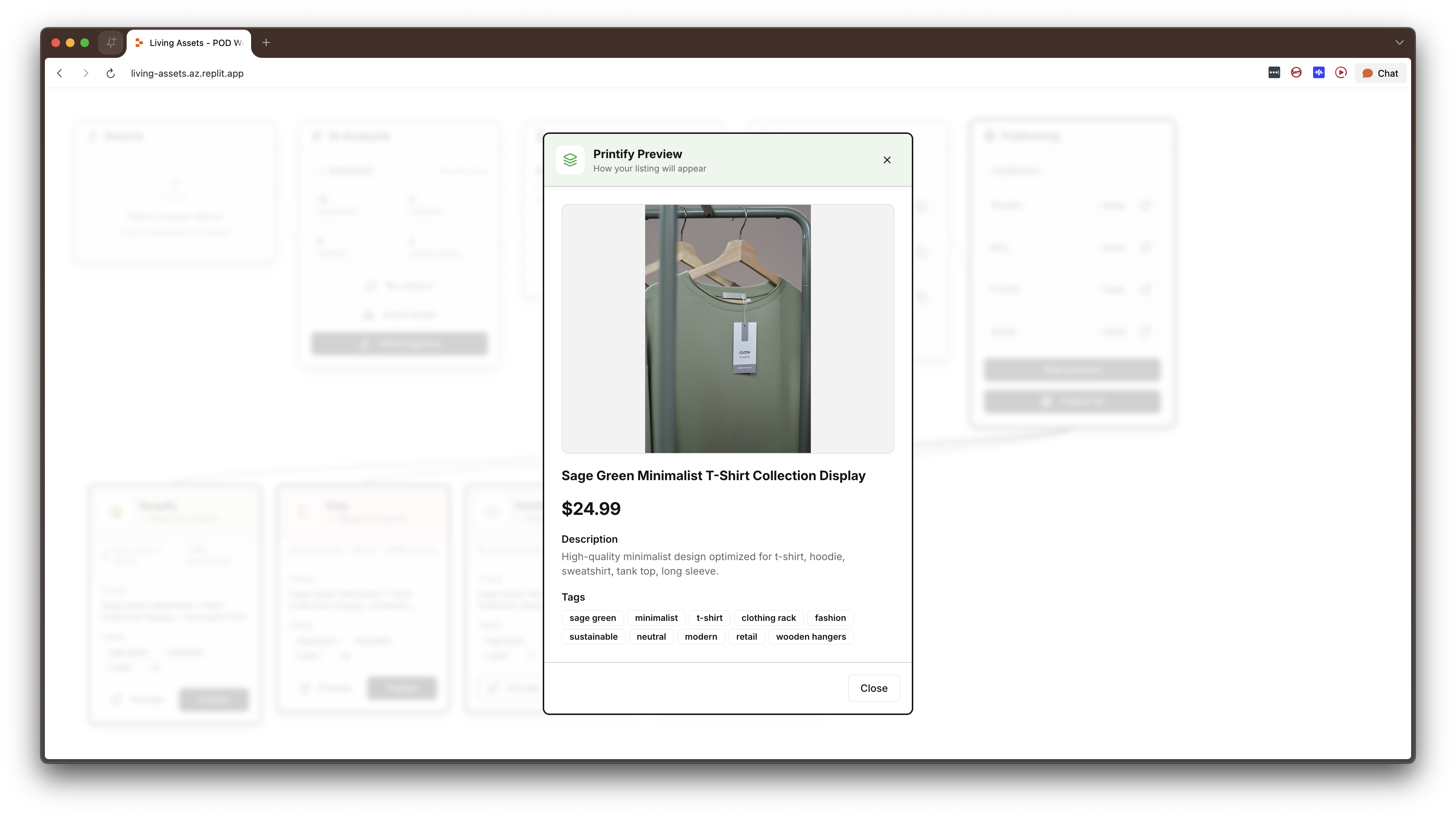
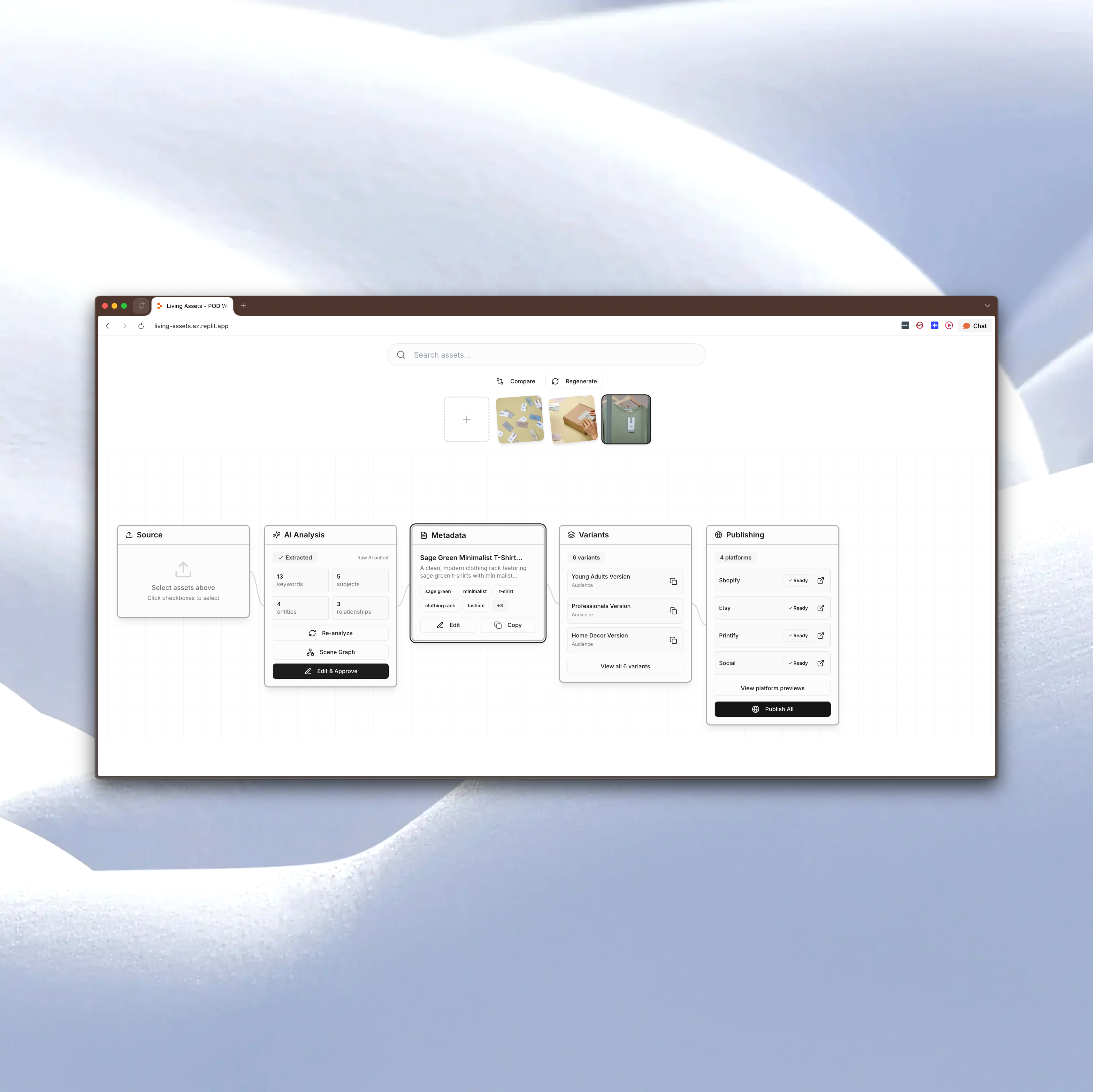
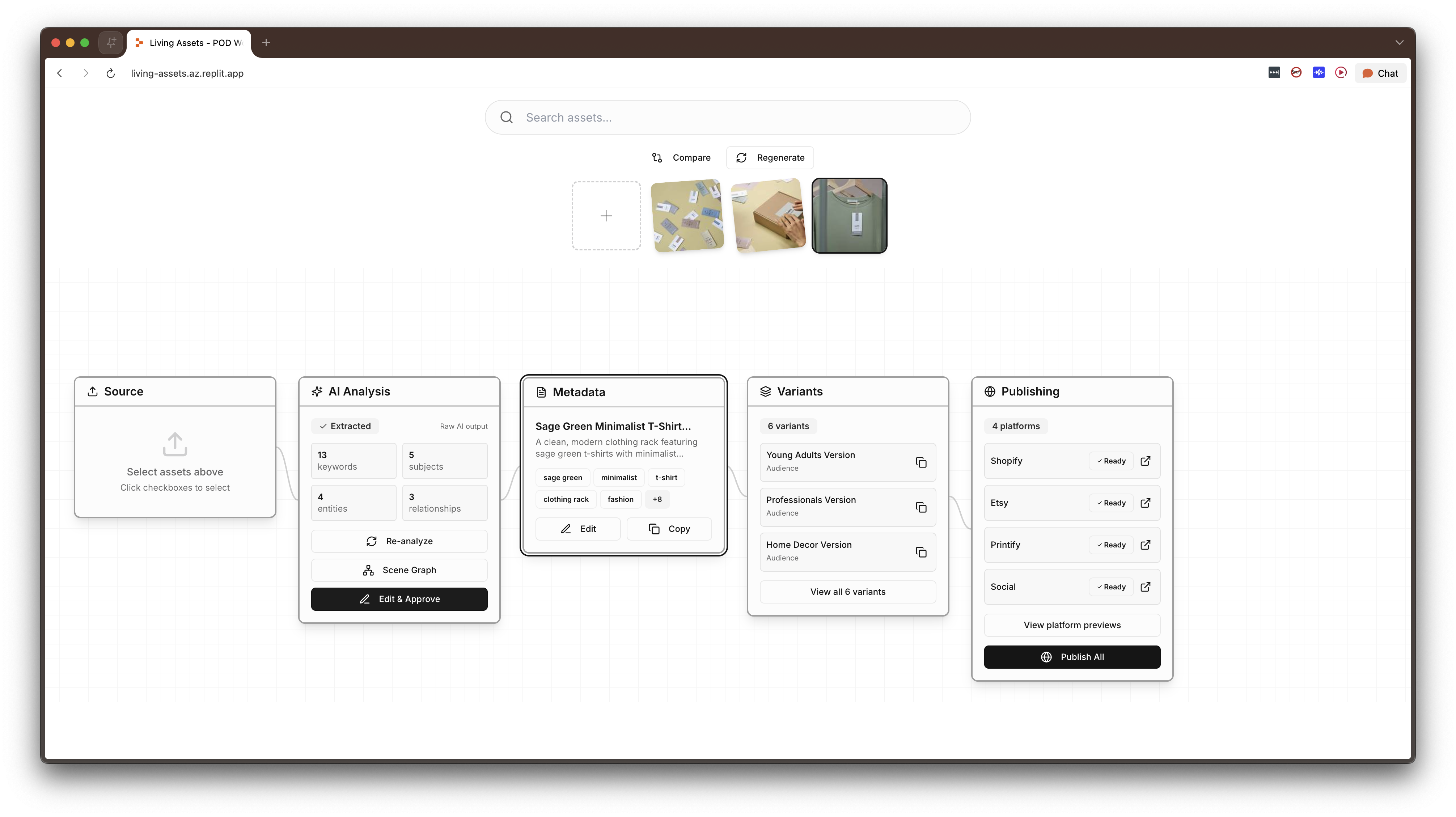
A full-stack application (~5,800 lines across 22 files, React + TypeScript + Express + PostgreSQL) built around a comprehensive JSON schema that makes an asset "living." The schema has six sections — Core, Creative, Commerce, AI Context, Relationships, and Lifecycle — plus a Scene Graph that represents what's actually in the image at an entity-relationship level. Every downstream operation in the system, including variant generation, platform publishing, SEO optimization, and bundle pricing, is driven entirely from this structured data, with no additional human input required after initial enrichment.
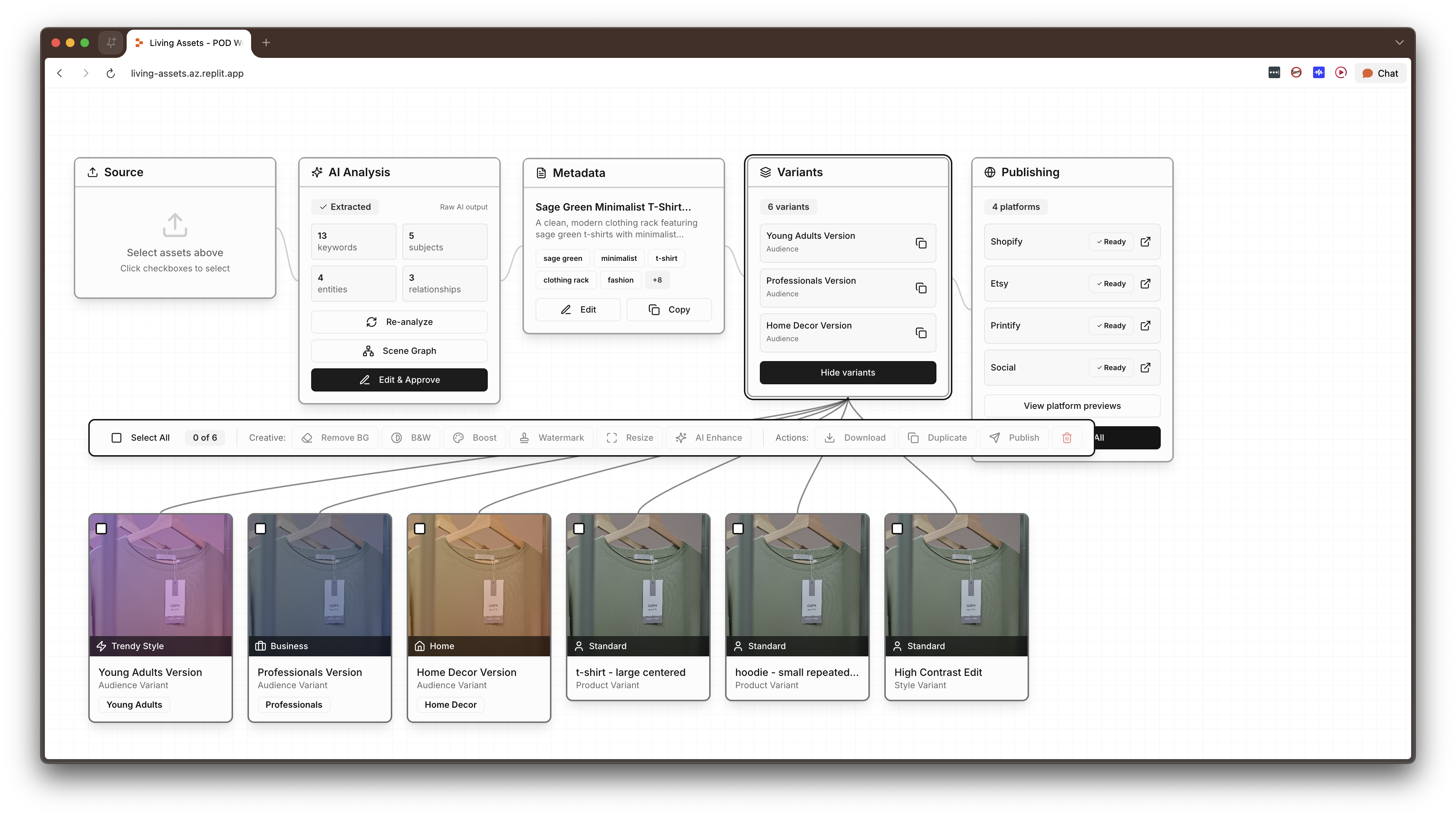
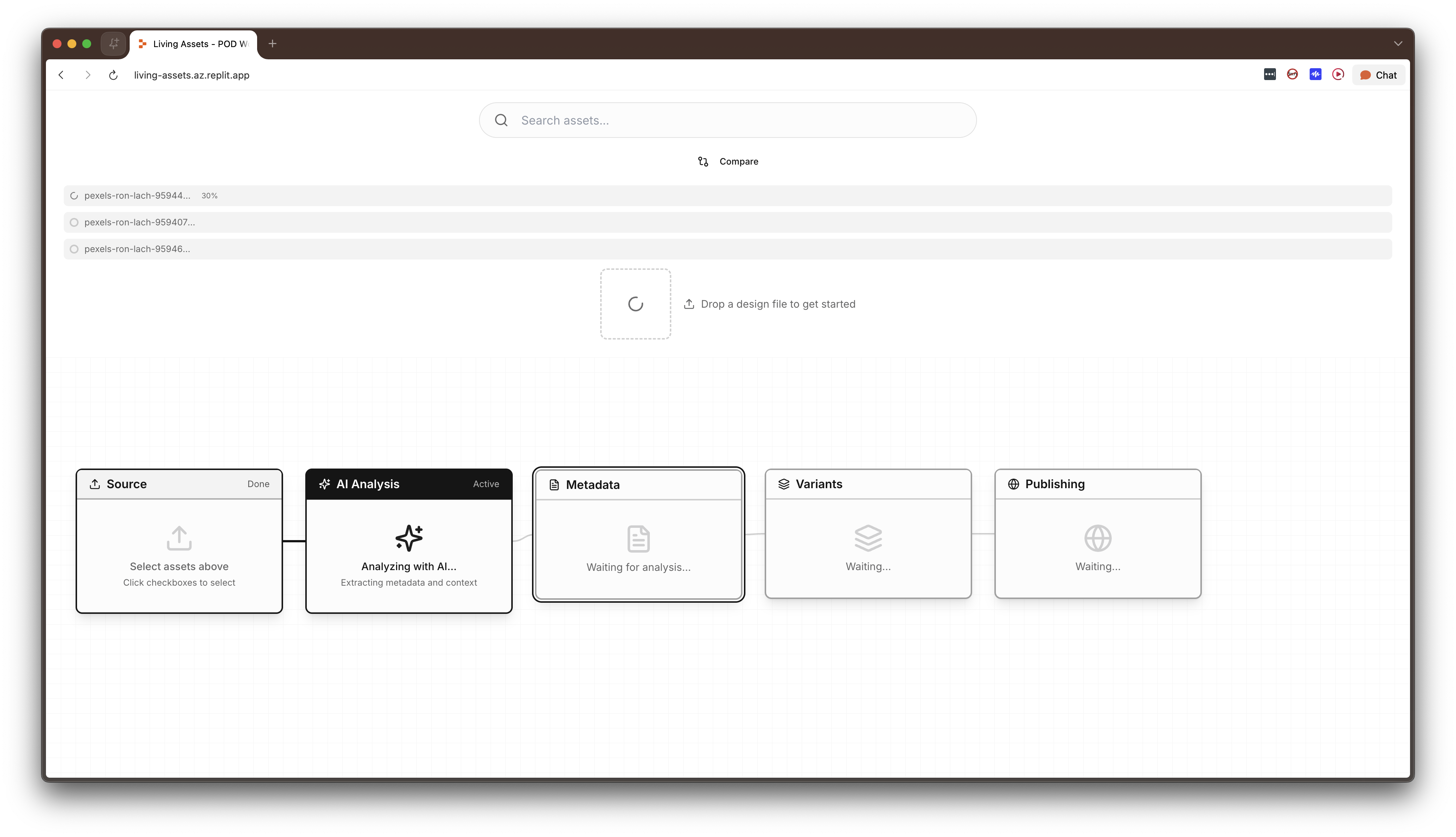
The interface is a horizontal five-node pipeline connected by animated SVG wire paths that pulse as data flows between stages. The pipeline metaphor is intentional: raw materials on the left, finished products on the right, with the transformation visible at every step.
Key design decisions:
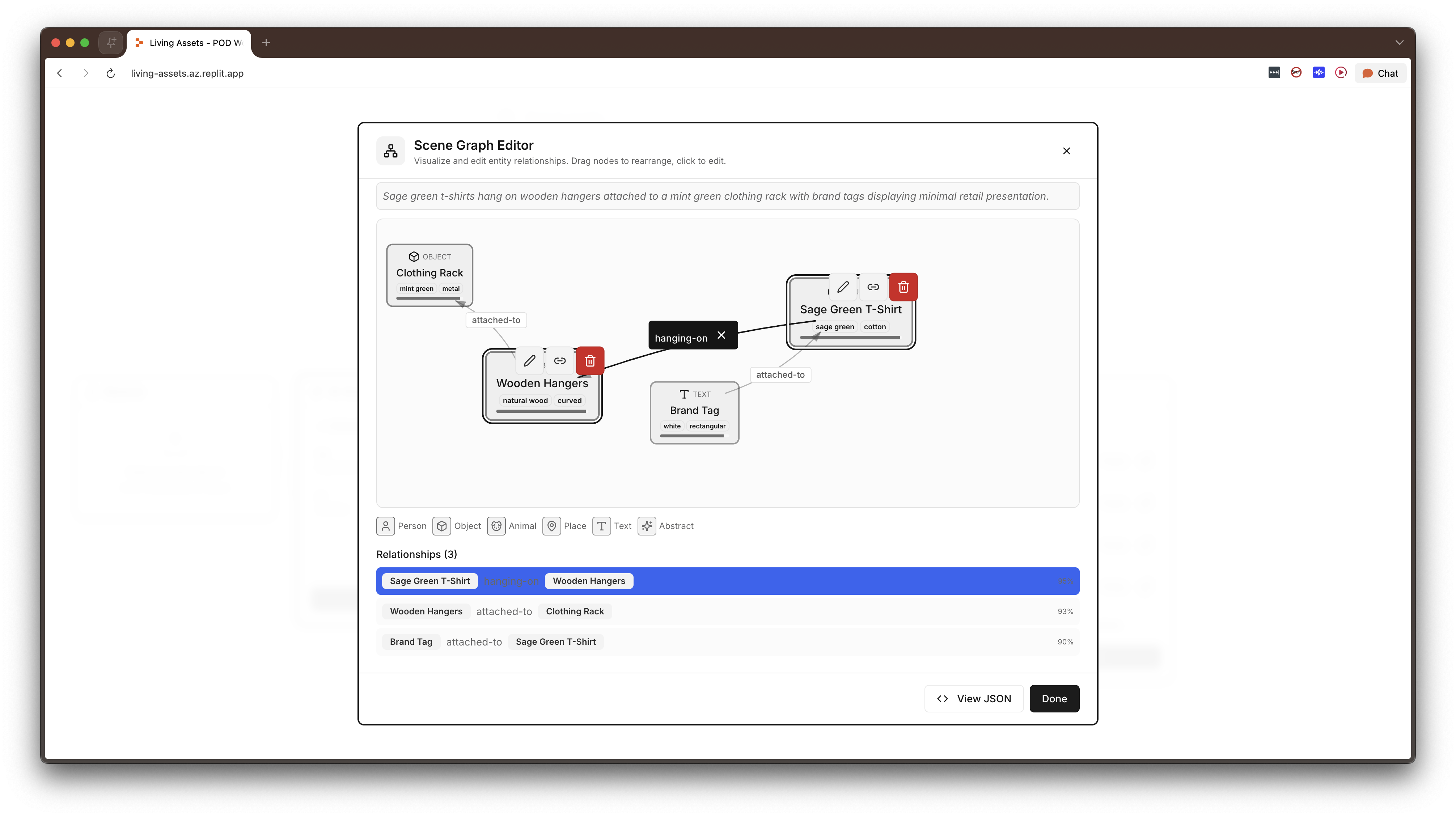
The Scene Graph.
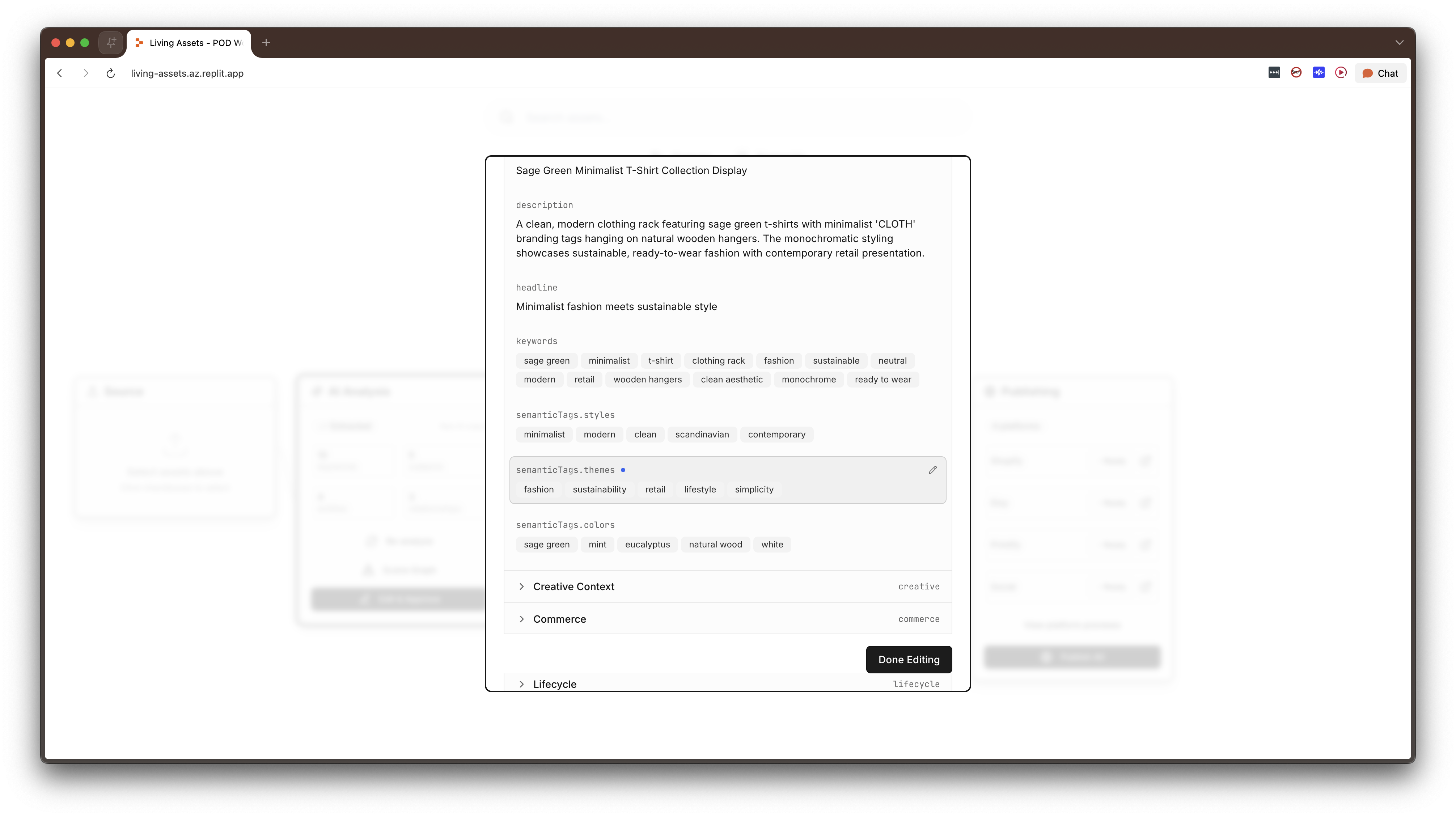
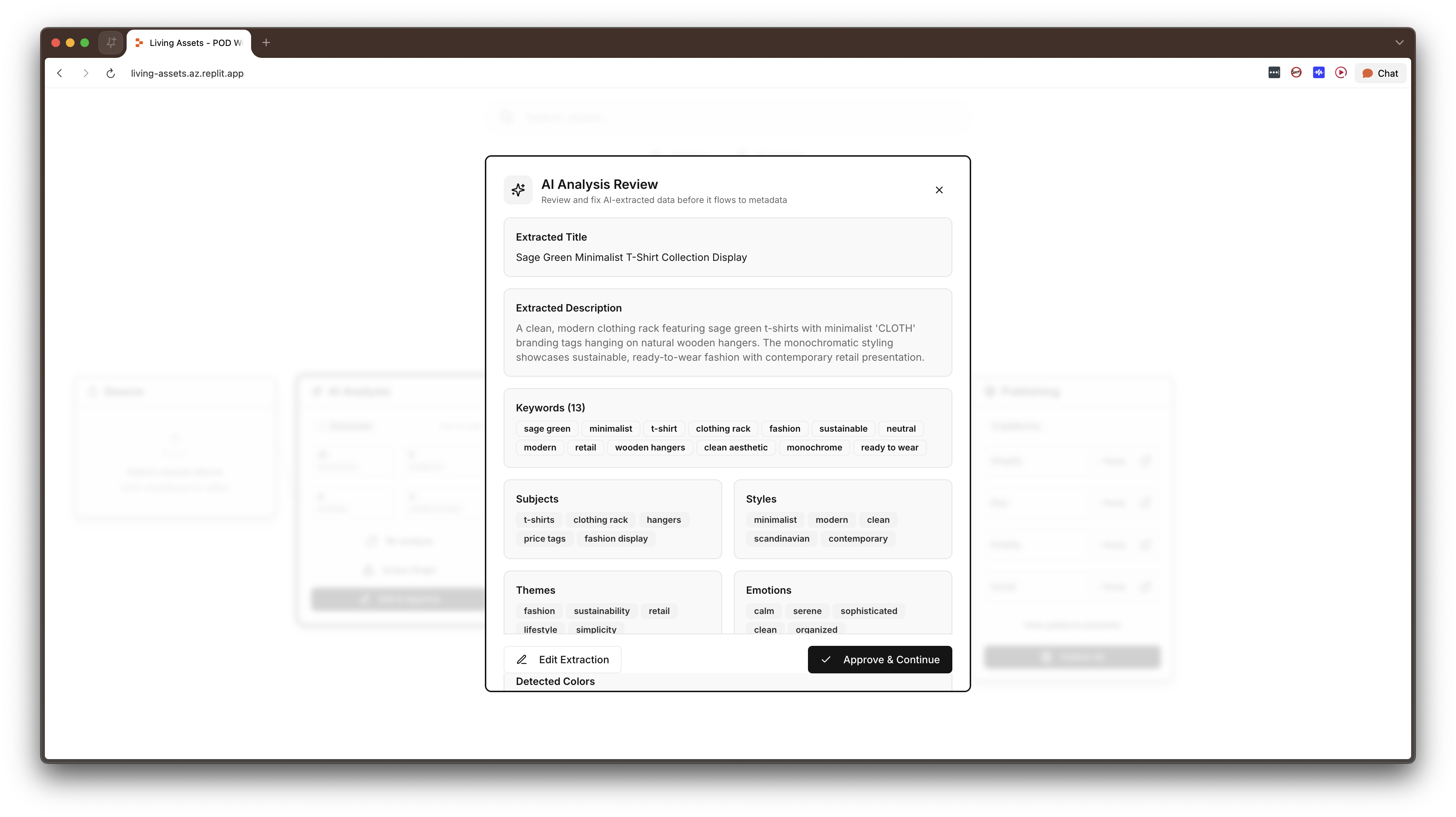
Rather than extracting flat keyword tags, the AI analysis produces a force-directed graph of entities (person, object, place, text, abstract) and the semantic relationships between them. For example: "girl eating cake," "fork on plate." This is editable: users can rename entities, change relationship predicates, add new nodes, delete incorrect ones. The editability was critical because it positions the AI's analysis is a starting point, not a final answer, and users need to be able to correct and extend it.
Auto-ripple updates. When a user corrects an AI mistake in one field, say, the AI called a river "Amazon" when it's the Nile, the system automatically finds and updates every other field containing that text: the description, Shopify title, Etsy title, meta description, alt text, everywhere. This exists because AI mistakes don't stay in one place. If the model gets something wrong, it's usually wrong everywhere. Fixing it once should fix it everywhere.
Trace highlighting. A bidirectional hover system (built as a React context wrapping the entire application) lets users hover any metadata field and see every variant and platform listing that used it light up, or hover any output and see every contributing input highlighted. This addresses the biggest usability risk in a system with lots of generated outputs: opacity. Users need to be able to ask "where did this come from?" and "what does this affect?" and get an immediate, visual answer.
Collection mode. When two or more assets are loaded, the system shifts to batch analysis, treating the assets as a group, calculating a cohesion score (0–100%) that quantifies how well they work together, identifying shared subjects and styles, and generating bundle pricing, collection listings, and coordinated publishing strategies across Shopify, Etsy, and Printify. Collection mode is automatic, not a toggle. If you have multiple assets selected, the system assumes you want to think about them as a group.
The prototype was built as a print-on-demand workflow, but the schema and pipeline generalize. The same architecture applies anywhere creatives generate assets for multiple contexts — social, editorial, product, brand — and currently spend that time manually re-describing, re-cropping, and re-uploading the same files.
And the tl;dr
What it makes possible
A world where creatives do their best work once, in the file, the way they already work, and the system handles the downstream distribution labor. Because the data is structured and enriched at the source, every downstream surface can be generated. And because the schema tracks relationships between assets, the system can reason about collections, suggest complementary pairings, and build coordinated commerce strategies from a single creative session.
Where this is going
The current model is unidirectional: file in, enriched artifacts out. The more interesting long-term question is what happens when those artifacts generate signal in the world. Engagement data, conversion rates, what resonates on which platform, all that data currently lives in dashboards, disconnected from the source file and inaccessible to the creative in any meaningful form. With five years of growth design background, the direction I want to take this is a closed loop: performance data feeding back into the asset's metadata, so the creative has a continuously enriched understanding of their own work, as a sort of as context that lives where they already work. The schema's Lifecycle and Relationships sections are already designed to support this. The publishing integrations and feedback hooks don't exist yet.